도입 사례로 살펴보는 올바른 Kafka 사용 방안
통상적으로 알려진 Kafka의 이점
Kafka는 링크드인에서 만들어져 현재는 Apache 재단에서 관리하는 오픈소스 분산 이벤트 스트리밍 플랫폼이다. 기존 링크드인의 데이터 처리 구조는 아래 이미지와 같이 굉장히 복잡했다고 한다. 이런 복잡한 구조에서 만약 이슈가 발생한다면 관련 시스템들을 하나하나 확인하며 문제를 해결해야 할 것이다. 그만큼 문제 해결에 어려움을 겪게 되어 생산성이 떨어질 것이다.
또한 모듈이나 데이터를 확장해야 하는 경우에도 많은 리소스가 들 것이다. 물론 기존과 같은 형식으로 확장한다면 그나마 괜찮겠지만, 다른 팀에서 새로운 방식으로 개발하게 된다면 파이프라인 확장이 어려워질 것임이 틀림없다.
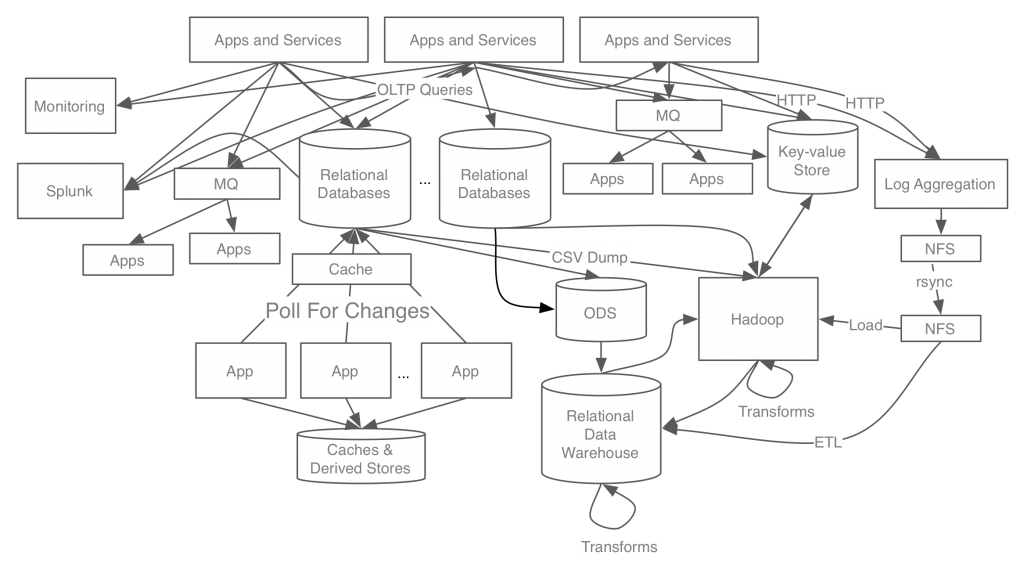
즉 결론적으로 데이터 전송 중앙화 부재의 문제를 해결하기 위해 Kafka를 개발했다고 볼 수 있다. Kafka는 확장성을 가지기 어려운 end-to-end로 데이터를 직접 전달하는 방식에서, 전송 중앙화를 사용하여 복잡한 시스템 구조에서 데이터 전송/수신에 큰 이점을 가진다.
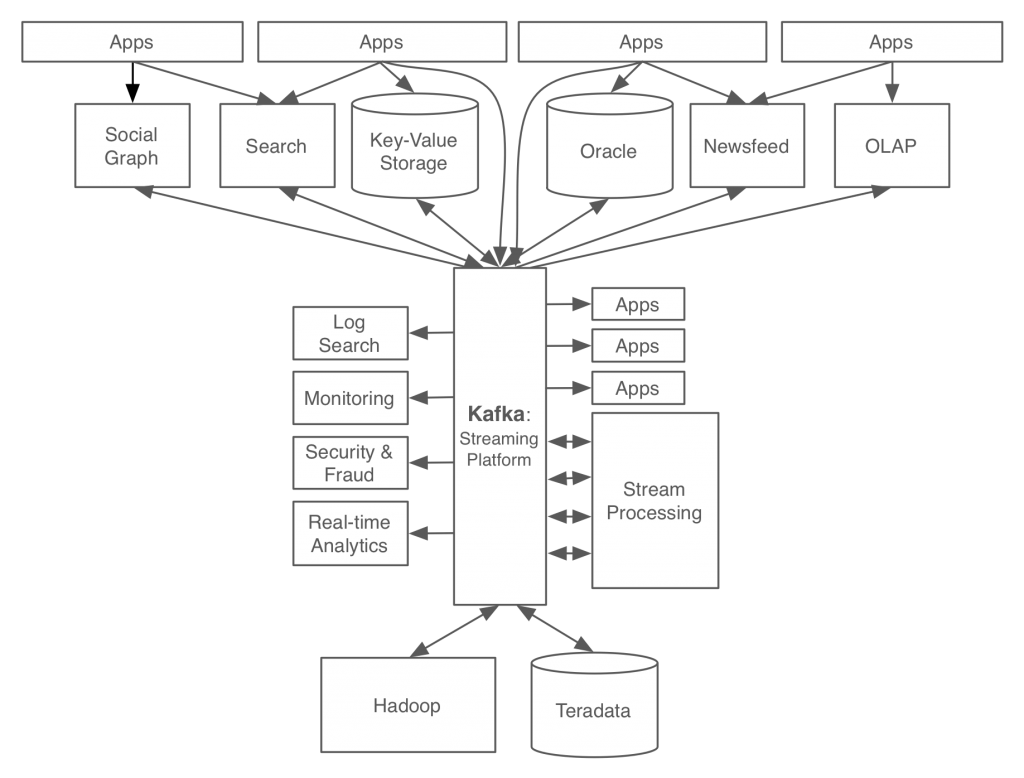
Zalando 기업의 Kafka 도입 사례
초기 Zalando는 RestAPI로 CRUD 동작을 수행하는 식으로 DB 상태를 변경시키고 변경 이벤트가 필요한 곳으로 outbound 이벤트를 전달하는 구조였다. 이러한 구조에서 고려해야 할 사항들이 많았는데, 오차는 줄일 수 있어도 동기화 방식에서 한계점이 존재했기 때문이었다.
- 다수의 클라이언트와 다양한 네트워크 환경에서 지연 없는 올바른 이벤트 전달 문제
- MSA와 같이 쪼개진 수 많은 서비스에서 Event Stream을 통해 전달받은 이벤트를 Consuming 하는데 outbound 이벤트가 불일치하거나 일부 데이터가 누락되는 경우, 데이터의 신뢰성 문제
- RestAPI 기반 통신을 하는 경우 동일한 데이터를 동시에 수정할 때 각각의 데이터에 대한 순서 보장과 전송 시의 순서 보장 문제
- 데이터 사용자들의 요구사항이 제각각 다르다면 outbound 이벤트를 전달하는 부분에서 각각의 요구사항에 맞는 구현이 필요한 문제
- 빠른 전송과 대량의 벌크 전송이 힘든 문제
위와 같은 문제를 해결할 대안으로 Kafka를 도입했다. Zalando가 Kafka를 선택하게 된 Kafka의 이점으로는 다음을 꼽았다.
- 빠른 데이터 수집이 가능한 높은 처리량
- 이벤트가 Kafka로 처리되는 응답시간은 한 자릿수의 밀리초(ms) 단위이다.
- 순서 보장
- Kafka는 같은 파티션에 담긴 이벤트에 대해서는 순서가 보장되면서 엔티티 간 유효성 검사, 동시 수정 문제가 해결된다.
- 적어도 한 번 전송 방식
- 멱등성 (동일한 요청을 한 번 보내는 것과 여러 번 연속으로 보내는 것이 같은 경우)
- Producer는 메시지를 브로커에게 전달한다.
- 브로커는 메시지 A를 받고, 잘 받았다는 ack를 Producer에게 전달한다.
- ack를 받게 되면 Producer는 다음 메시지를 전달하고 ack를 받지 못했다면 해당 메시지를 재전송한다.
- 위와 같이 메시지를 소비하는 Consumer에서 중복에 대한 처리를 하고 메시지를 재전송할지라도 메시지에 대한 유실은 없도록 하는 것이 적어도 한 번 전송 방식이다.
- 멱등성 (동일한 요청을 한 번 보내는 것과 여러 번 연속으로 보내는 것이 같은 경우)
- 자연스러운 백프레셔 핸들링
- 백프레셔 (Back pressure): 이벤트가 들어오는 속도보다 이벤트를 처리하는 속도가 느려 이벤트 Input이 급격히 쌓이는 현상
- pull 방식
- Consumer가 브로커로부터 직접 메시지를 pull 하는 방식
- push 방식
- 브로커가 Consumer에게 메시지를 직접 push 해주는 방식
- push 방식은 브로커가 보내주는 속도에 의존해야 한다는 한계가 존재
- Kafka는 pull 방식을 채택해서 간단하게 클라이언트 구현 가능하다.
- 강력한 파티셔닝
- 카프카의 파티셔닝 기능을 활용하면 topic을 여러 개로 나눠서 사용할 수 있다.
- 파티션에 적절한 키를 할당하기 위한 고려사항은 존재하나 각 파티션들은 다른 파티션들과 관계 없이 처리할 수 있어 효과적인 수평 확장이 가능하다.
- 비동기
- Producer와 Consumer 간 비동기 방식
- Producer가 메시지를 브로커에게 전달하면 Consumer는 원하는 topic에 해당하는 메시지를 pull 할 뿐이다.
- 새로운 애플리케이션이 나중에 메시지를 읽어가는 방식에도 문제가 되지 않는다.
Twitter 기업의 Kafka 도입 사례
Twitter의 주요 기능인 팔로우 또는 좋아요를 하게 되면 팔로워에게 메시지를 전달하는 기능, 리트윗을 하게 되면 팔로워 타임라인에 전달하는 기능에서 문제 상황이 발생했다. 최대한 이러한 소식을 빠르게 노출시켜야 했고, 더 많은 실시간 사용 사례를 다뤄야 했다.
Twitter의 경우에는 자체적인 In-House EventBus를 사용하다 Kafka가 성장하고 난 후로 Kafka로 전환을 하게 되었는데, 전환하게 된 목적은 크게 비용 절감과 커뮤니티로 꼽을 수 있다.
In-House EventBus는 Kafka 보다 동일한 업무 부하를 처리하기 위해 더 많은 시스템을 필요로 했다. 단일 소비자 사용 사례의 경우 리소스를 약 68% 절약하고, 여러 소비자 사용 사례의 경우 리소스가 약 75% 절약되었다.
커뮤니티 적인 측면으로는 우선 EventBus에서 필요로 하는 기능들이 이미 Kafka에서 구현이 되어 있었다는 점, 클라이언트나 브로커에 문제가 발생할 경우 관련 문제에 대해 웹에서 정보 수집이 용이하다는 점, 유지 보수를 위해 Kafka를 다룰 수 있는 엔지니어를 고용하는 게 더 쉽다는 점을 꼽을 수 있다.
Netflix 기업의 Kafka 도입 사례
Netflix에서는 주로 데이터 수집, 통계, 처리, 적재하기 위한 파이프라인을 연결하는 역할로 Kafka를 사용한다. 비디오 시청 활동, 사용자의 사용 빈도, 에러 로그 등 모든 이벤트가 데이터 파이프라인을 통해 흐르게 된다.
Kafka가 해결 방안이 되는 주요 문제 상황
정리해보면 다음과 같은 문제 또는 고민이 있는 경우에 Kafka는 충분한 해결 방안이 될 것으로 보인다.
- 동기 / 비동기 데이터 전송에 대한 고민이 있는지?
- 실시간 데이터 처리에 대한 고민이 있는지?
- 현재 데이터 처리량에 대한 한계를 느끼는지?
- 현재 데이터 파이프라인이 복잡하게 느껴지는지?
- 데이터 처리의 비용 절감에 고민이 있는지?
정리하며
실제 기업에서 Kafka를 도입한 사례를 찾아보니 다양한 문제의 해결 방안으로 사용하고 있다는 걸 알게 되었고, Kafka는 이제 이벤트 스트림 플랫폼을 넘어 데이터 처리 프로세싱의 핵심이 아닌가 하는 생각이 들었다. 이는 데이터 처리에 대한 웬만한 문제를 Kafka를 통해 해결하고 있는 모습이 보여졌기 때문일 것이다.
또한 이전 포스팅 글에서 순서가 보장되어야 하는 이벤트를 Kafka를 사용해서 처리하는 구조가 맞는지 의문이 들었다고 했는데, Zalando 기업에서는 오히려 순서 보장을 위해 Kafka를 사용하는 사례를 보고, ‘순서 보장 또한 Kafka의 이점으로 고려할 수 있구나!’ 하고 깨닫게 되었다.
이제 Kafka가 해결 방안이 되는 주요 문제 상황들을 실무에서 마주하게 된다면 Kafka 도입에 긍정적으로 고려해볼 수 있을 것이다.
참고 자료
Putting Apache Kafka To Use: A Practical Guide to Building an Event Streaming Platform
Why Event Driven? - Zalando Engineering Blog
Twitter’s Kafka adoption story - X Engineering Blog
Evolution of the Netflix Data Pipeline - Netflix Tech Blog
{kind=link}